SUBJECT: 데이터베이스 기본 쿼리문을 파악하고 이해하자
References
- https://www.w3schools.com/mysql/default.asp
- text book, Learning sql 3rd edition
BASICS
TERMINOLGY
- Entity
- Something of interest to the database user community.데이터베이스의 유저들이 흥미를 갖는 대상, 예시로는 고객, parts, 지정학적 위치 등이 있다.
- Column
- An individual piece of data stored in a table테이블에 저장된 개별적인 데이터 부분으로의 유닛
- Row (Record)
- set of Columns, 함께 모여서 완전하게 entity 혹은 entity의 어떤 action을 설명할 수 있는 것.
- Table
- A set of rows, 메모리에 영구적으로 혹 은 비영구적으로 로드되는 데이터의 뭉치
- Result Set
- nonpersistent table의 또 다른 이름, 일반적으로 SQL쿼리에 대한 결과가 해당된다.
- Primary Key
- 하나 혹은 복수의 columns로, 유니크한 구분자로 각 테이블의 row를 상징할 수 있는 column
- Foreign Key
- 하나 혹은 복수의 columns로, 다른 테이블의 하나의 row를 구별해주는 column
- Database transaction
- DBMS내에서, 실행의 단위를 상징하며, 다른 transaction에 대해서 독립적이며 믿을 수 있는 것으로 취급된다.2개의 큰 목적을 지니고 있다.
- 믿을 수 있는 작업들을 제공하며, 실패에서 회복하고, 데이터 베이스를 실패의 경우에도 지속적인 것으로 한다.
- 데이터베이스에 동시적으로 접근하는 프로그램들에 대해서 분리, 고립을 제공한다.
SQL 이란?
SQL 진술 classes
- SQL schema statement (DDL)
- 데이터베이스에서 데이터 구조를 정의하는데 사용된다.모든 데이터베이스 요소들은 이것으로 생성되며, data dictionary라고 불리는 데이터베이스를 위한 데이터에 저장된다.
CREATE TABLE corporation (corp_id SMALLINT, name VARCHAR(30), CONTRAINT pk_corporation PRIMARY KEY (corp_id) );
- SQL data statement (DML)
데이터베이스에서 데이터 구조를 조작한는데 사용된다.
INSERT INTO coporation (corp_id, name) VALUES (27, 'Acme Paper Corporation');
- SQL transaction statement
- 시작과 끝, 그리고 되돌리는 transaction에 사용된다.
SQL DML statements
GROUP BY
- DESC
- GROUP BY 진술은 일반 rows를 같은 값으로 평가된 것을 요약화된 rows로 그룹화합니다.
- EXAMPLE
- 예를 들면, find the number of customers in each country
- 각 나라별 소비자의 숫자. / 도시(공통키워드) / customer 별로 country 정보가 있을 것이다.
SYNTAX
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY
- DESC
- ORDER BY 키워드는 result-set을 오름차순, 내림차순으로 정렬하는 데에 사용됩니다.
- ORDER BY 키워드는 records들을 기본적으로 asc(오름차순)으로 정렬하고, DESC 키워드를 통해 내림차순으로 정렬할 수 있습니다.
SYNTAX
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
MIN MAX Function
- DESC
- MIN()는 선택한 column에서 가장 작은 값을 반환합니다.
- MAX()는 선택한 column에서 가장 큰 값을 반환합니다.
SYNTAX
SELECT MIN(column_name)
FROM table_name
WHERE condition;
COUNT Function
- DESC
- COUNT()는 명시한 조건을 만족하는 Rows의 수를 반환합니다.
SYNTAX
SELECT COUNT(column_name)
FROM table_name
WHERE condition;
AVG Function
- DESC
- AVG()는 명시한 조건을 만족하는 column(numeric)에 해당하는 row들의값의 평균을 반환합니다.
SYNTAX
SELECT AVG(column_name) # STRING TYPE X order by와 다르다.
FROM table_name
WHERE condition;
ALIASES
- DESC
- aliases들은 테이블 혹은 테이블의 필드에 대해서 temporary name을 부여합니다.
- aliases들은 column(필드)의 이름을 더욱 가독성 있게 만들어줍니다.
- 지정한 aliases들은 해당 쿼리에 대해서만 유효합니다.
- aliases들은 AS키워드를 통해 생성됩니다.
SYNTAX
SELECT column_name AS alias_name
FROM table_name;
SELECT column_name
FROM table_name AS alias_name;
JOIN
- DESC
- JOIN구문은 두 개 혹은 그 이상의 테이블들을 결합할 떄 사용됩니다. 기본적으로 그들의 관련된 필드를 통해서 가능합니다. ON
- ON이 없다면?
- 원칙적으로 사용이 불가능하지만, 아무 교차점이 없는 두 개의 테이블을 하나의 테이블에 필드를 생성해서 연결하는 것을 따로 가져오는 것보다 좋은 선택이 아닐 것 같습니다.
TYPES
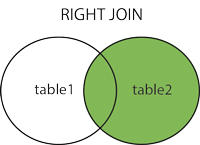
INNER JOIN: 각 테이블에서 matching value를 가진 record을 반환합니다.
두 테이블에 교집합으로 지정한 필드가 유효한 record만 반환하기 때문에, 완전 테이블을 획득 가능합니다.
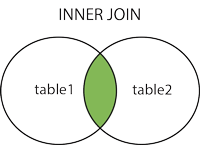
LEFT JOIN: 좌측 테이블의 모든 레코드와, 그와 match되는 우측 테이블의 record를 함께 반환합니다.
두 테이블 중 LEFT에 RIGHT의 교집합을 붙이는 방식으로 LEFT의 일부는 RIGHT가 연결되지 않을 수 있다.
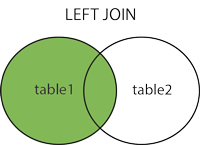
RIGHT JOIN: 우측 테이블의 모든 레코드와, 그와 match되는 좌측 테이블의 record를 함께 반환합니다.
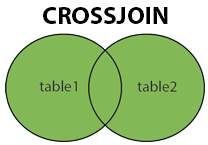
CROSS JOIN(fulljoin): 두 테이블의 모든 레코드를 반환합니다.
UNION
- DESC
UNION연산자는 2개 이상의 SELECT에 대한 result-set을 조합합니다.
모든 UNION 내부의 SELECT 진술은 같은 수의 columns, 즉 필드수가 동일해야 합니다.
columns, 필드들은 또한 반드시 유사한 데이터타입을 지녀야 합니다.
SELECT 진술 내부의 모든 columns, 필드들은 또한 반드시동일한 순서를 가져야 합니다.
- (name, id, date)
EXAMPLE
SELECT City, CustormName as Name FROM customers
UNION
SELECT City, SupplierName as Name FROM Suppliers
ORDER BY City;
Name City
Drachenblut Delikatessend Aachen
Rattlesnake Canyon Grocery Albuquerque
Old World Delicatessen Anchorage
Grandma Kelly's Homestead Ann Arbor
Gai pâturage Annecy
Vaffeljernet Århus
SUBQuery
- DESC
- 서브쿼리는 값에서부터 필드 혹은 테이블로 까지 치환이 가능하며, 참조 순서에 따라 correlated subquery라고 부르기도 합니다..
- 메인 쿼리보다 먼저 평가되면서도 해당 서브쿼리 밖의 네임스페이스까지 사용할 수 있습니다..
- 따라서 바깥 쿼리부터 평가해서 메모리에 적재하고, 단위별로 분류하면서 깊이가 깊은, 혹은 가장 나중에 정의된 서브쿼리부터 평가를 수행하여 바깥으로 돌아가면서 결과에 반영합니다.
wikipedia Example
- 고용자의 임금과 고용자의 학과별 임금을 한꺼번에 표시
SELECT employee_number, name FROM employee emps WHERE salary > ( SELECT AVG(salary) FROM employees # 고용인의 평균임금 WHERE emps.department = department # 학과별로 골라서 ); /* * INNER JOIN으로 학과별로 GROUP BY 를 학과별로 연결해서 처리할 수 있는데, * 동적으로 매 루프마다 employees 테이블을 1회씩 풀스캔합니다. */ SELECT employee_number, name, salary, survey.avg_salary FROM employee INNER JOIN ( # 전공별 임금 취합 SELECT department, AVG(salary) as avg_salary FROM employee GROUP BY department ) AS survey ON employee.department = survey.department
nested 쿼리의 내부 쿼리는 각 외부employee에 대해서 재실행 된다.
위 예시에서는 쿼리가 값으로 평가되고 있으며 밖의 emp에 대해 매회 수행되는 row를 이용한다.
A(A1(A2))의 쿼리가 존재한다면, A의 바깥 루프를 가장 먼저 수행하고, 그 값을 결과테이블에 반영하는 것이 아니라 A에서 수행되는 값들을 기억해놓은 상태로 A -> A1 -> A2 로 이동한다.
- A, A1의 메모리를 사용하여 A2에서 실행된 결과가 최종적으로 출력 테이블에 입력된다.
- 위의 경우에는,
emps.1(john), john의 임금
subq(john의 학과, employees.all의 학과에 대한 평균값)
where(john의 임금이 더 큰가?)
테이블의 row에 john의 number, name 저장
emps.2(amy)
순서로 진행이 되는데 마치 nested for loop 과 같다.
correlated 서브쿼리는 또한 WHERE을 제외한 어디서든 등장할 수 있다.
- WHERE은 조건문이 들어오는 곳이어서 서브쿼리 2개를 조건문으로 양쪽 항으로 값으로 평가해서 사용한다면 가능하지만 서브쿼리하나가 조건문의 평가 결과로 사용될 수 는 없다., (SQ.value) in (SQ.table) (O)/ WHERE (SQ) (X)
- 이 얘기가 아니었다, (WHERE outer.name in (SELECT..) 에서 WHERE은 subquery로 지정할 수 없다는 얘기이다.
예를 들어 위의 쿼리는 SELECT구문 내부에서 서브쿼리로 사용하여 > 평가식의 우측항의 값으로 사용한다.
일반적으로 FROM구문의 우측항을 대상으로 서브쿼리를 사용하는 것은 의미가 없다고 여겨진다.
- 왜냐하면 이것은 치킨과 닭의 문제다. (main query는 from table에서 기인하는데, 해당 table이 서브쿼리라면, 해당 서브쿼리가 참조할 바깥 공간이 없기 때문에 단순히 테이블을 해당 테이블 내에서 필터링하는 결과로만 사용할 수 있기 때문에 그렇다.)
(4-3 6:20)에서 왜인지 from구에서 사용하는게 가장 많이 사용한다고 한다.
SELECT pu.user_id, pu.point, a.avg_likes FROM point_user pu INNER JOIN ( SELECT user_id, ROUND(AVG(likes), 1) AS avg_likes FROM checkins group by user_id) ) AS A ON pu.user_id = A.user_id
SubQuery FROM을 해결하기 위한 WITH
# 코스별 시작 유저 분포
SELECT ch.course_id,
COUNT(DISTINCT(ch.user_id)) AS c_users
FROM checkins ch
GROUP BY ch.course_id;
# 코스별 주문 수
SELECT o.course_id,
COUNT(o.user_id) AS o_orders
FROM orders o
WHERE o.course_id
GROUP BY o.course_id;
# 두 개를 합쳐서 총 주문 수에 대한 사용 유저의 비율을 계산합니다.
SELECT ch.course_id,
ch.c_users,
o.o_orders,
(ch.c_users / o.o_orders) AS ratio
FROM (
SELECT course_id,
COUNT(DISTINCT(user_id)) AS c_users
FROM checkins
GROUP BY course_id
) AS ch INNER JOIN
(
SELECT course_id, count(user_id) AS o_orders
FROM orders
WHERE course_id
GROUP BY course_id
) as o on ch.course_id = o.course_id;
## 복잡합니다.
WITH user_table AS ( #SUBQUERY1
SELECT course_id,
COUNT(DISTINCT(user_id)) AS c_users
FROM Checkins
GROUP BY course_id
), order_table AS ( #SUBQUERY2
SELECT course_id, COUNT(user_id) AS o_orders
FROM Orders
WHERE course_id
GROUP BY course_id
) SELECT # <- 이 부분부터
user_table.course_id,
user_table.c_users,
order_table.o_orders,
(user_table.c_users / order_table.o_orders) AS ratio # <- 결과 필드 정의
FROM user_table
INNER JOIN order_table # <- 테이블 조합
ON user_table.course_id = order_table.course_id;
- 메인 SQL은 테이블에서 필드를 가져오거나 테이블을 조합하는 것으루 이루어지는데, 필드 정의에 Sub SQL이 들어와서 난잡했었습니다.
- Sub SQL를 상단으로 분리하고 하단에서는 결과를 정의하는 메인 SQL만 남겨 분명하게 정의되었습니다.
활용빈도가 높은 FUNCTION
SUBSTRINGINDEX(Target, delimiter, indexto)
- Target의 delimiter로부터 indexto까지 index를 잘라내 줍니다.
# email = king123@google.com SUBSTRINGINDEX(email, "@", 1) AS account, # king123 SUBSTRINGINDEX(email, "@", -1) AS domain # google.com
SUBSTRING(Target, indexFrom, count)
- Target의 indexFrom로부터 count만큼 문자열을 반환합니다.
# email = king123@google.com SUBSTRINGINDEX(email, 0, 7) AS account, # king123 SUBSTRINGINDEX(email, 8, 10) AS domain # google.com
Case
DESC
- 필드에 대해서 IF-THEN-ELSE-FI 를 수행합니다.
- WHEN의 조건을 만났을때, 값을 평가하고 CASE를 벗어납니다.
SELECT OrderID, Quantity,
CASE
WHEN Quantity > 30 THEN 'The quantity is greater than 30'
WHEN Quantity = 30 THEN 'The quantity is 30'
ELSE 'The quantity is under 30'
END AS QuantityText
FROM OrderDetails;